



数据是区块链技术的关键,是开发去中心化应用程序 (dApp) 的基础。虽然目前的大部分讨论都围绕着数据可用性 (DA)——确保每个网络参与者都可以访问最近的交易数据进行验证——但还有一个同样重要的方面经常被忽视:数据可访问性。
Data are the key to block chain technology and the basis for developing decentralised applications (dApp). While much of the discussion now revolves around data availability (DA) - ensuring that every network participant has access to recent transaction data for validation - an equally important aspect is often overlooked: data accessibility.
在模块化区块链时代,DA 解决方案已变得不可或缺。这些解决方案确保所有参与者都可以使用交易数据,从而实现实时验证并维护网络的完整性。然而,DA 层的功能更像是广告牌而不是数据库。这意味着数据不会无限期地存储;它会随着时间的推移而被删除,就像广告牌上的海报最终会被新海报取代一样。
In the age of modular block chains, the DA solutions have become indispensable. These solutions ensure that all participants have access to transactional data to verify and maintain the integrity of the network in real time. However, the DA layer functions more like a billboard than a database. This means that the data will not be stored indefinitely; it will be deleted over time, as the poster on the billboard will eventually be replaced by a new poster.
另一方面,数据可访问性侧重于检索历史数据的能力,这对于开发 dApp 和进行区块链分析至关重要。这一方面对于需要访问过去数据以确保准确表示和执行的任务至关重要。尽管数据可访问性很重要,但讨论得较少,但它与数据可用性一样重要。两者在区块链生态系统中发挥着不同但互补的作用,全面的数据管理方法必须解决这两个问题,以支持强大而高效的区块链应用程序。
Data accessibility, on the other hand, focuses on the ability to retrieve historical data, which is essential for the development of dApp and block chain analysis. This aspect is critical for tasks that require access to past data to ensure accurate presentation and implementation. While data accessibility is important, it is less discussed, but as important as data availability.
自诞生以来,区块链就彻底改变了基础设施,并推动了游戏、金融和社交网络等各个领域的去中心化应用程序 (dApp) 的创建。然而,构建这些 dApp 需要访问大量区块链数据,这既困难又昂贵。
Since its inception, the block chain has radically changed infrastructure and promoted the creation of decentralised applications (dApp) in various fields, such as games, finance and social networking. However, it is difficult and expensive to construct these dApps, which require access to a large number of block chain data.
对于 dApp 开发者来说,一种选择是托管和运行自己的存档 RPC 节点。这些节点从一开始就存储所有历史区块链数据,允许完全访问数据。但是,维护存档节点的成本很高,查询能力也有限,因此无法以开发人员需要的格式查询数据。虽然运行较便宜的节点是一种选择,但这些节点的数据检索能力有限,这可能会妨碍 dApp 的运行。
For dApp developers, one option is to host and run their own archived RPC nodes. From the outset, these nodes store all historical block chain data, allowing full access to the data. However, maintaining archived nodes is costly and search capabilities are limited, so data cannot be searched in the format required by the developers. While running less expensive nodes is an option, these nodes have limited data retrieval capacity, which may hinder dApp operations.
另一种方法是使用商业 RPC(远程过程调用)节点提供商。这些提供商负责节点的成本和管理,并通过 RPC 端点提供数据。公共 RPC 端点是免费的,但有速率限制,可能会对 dApp 的用户体验产生负面影响。私有 RPC 端点通过减少拥塞提供更好的性能,但即使是简单的数据检索也需要大量的来回通信。这使得它们请求繁重,对于复杂的数据查询效率低下。此外,私有 RPC 端点通常难以扩展,并且缺乏跨不同网络的兼容性。
Another approach is to use commercial RPC (remote process calls) node providers. These providers are responsible for the cost and management of nodes and for providing data through RPC endpoints. Public RPC endpoints are free, but there are speed limits that may negatively affect the dApp user experience. Private RPC endpoints provide better performance by reducing congestion, but even simple data retrieval requires a lot of incoming and outgoing communications. This makes them demanding and inefficient for complex data search. Moreover, private RPC endpoints are often difficult to expand and lack compatibility across different networks.
区块链索引器在组织链上数据并将其发送到数据库以便于查询方面起着至关重要的作用,这就是为什么它们经常被称为「区块链的谷歌」。它们的工作原理是索引区块链数据并通过类似于 SQL 的查询语言(使用GraphQL等 API)使其随时可用。通过提供查询数据的统一界面,索引器允许开发人员使用标准化查询语言快速准确地检索所需的信息,从而大大简化了流程。
Block chain indexers play a crucial role in organizing the data on the chain and sending them to the database for ease of search, which is why they are often referred to as " Google of the block chain ". They work on the principle that index block chain data are readily available through querying languages similar to SQL (using APIs such as GraphQL). By providing a uniform interface for query data, the indexer allows developers to quickly and accurately retrieve the required information in standardized query languages, thus significantly simplifying the process.
不同类型的索引器通过各种方式优化数据检索:
Different types of indexers optimize data retrieval in a variety of ways:
1. 完整节点索引器:这些索引器运行完整的区块链节点并直接从中提取数据,确保数据完整准确,但需要大量的存储和处理能力。
Complete node indexers: These indexers run complete block chain nodes and extract data directly from them to ensure that the data are complete and accurate, but require significant storage and processing capacity.
2. 轻量级索引器:这些索引器依靠完整节点根据需要获取特定数据,从而减少存储要求但可能会增加查询时间。
2. Lightweight indexers: These indexers rely on complete nodes to obtain specific data as required, thereby reducing storage requirements but may increase query time.
3. 专用索引器:这些索引器专门针对某些类型的数据或特定的区块链,可优化特定用例的检索,例如 NFT 数据或 DeFi 交易。
3. Specialized indexers: These indexers are specific to certain types of data or specific block chains and optimize access to specific cases, such as NFT data or DeFi transactions.
4. 聚合索引器:这些索引器从多个区块链和来源提取数据,包括链下信息,提供统一的查询界面,这对于多链 dApp 特别有用。
4. Polymeric indexers: These indexers extract data from multiple block chains and sources, including information under the chain, and provide a uniform query interface, which is particularly useful for multi-chain dApp.
仅以太坊就需要 3TB 的存储空间,并且随着区块链的不断增长,Erigon 存档节点的数据存储量也会不断增加。索引器协议部署了多个索引器,可以高效地索引和高速查询大量数据,这是 RPC 无法实现的。
As the chain of blocks grows, the storage of data at the Erikon archive node will increase. The indexer protocol has multiple indexers that can efficiently index and search a large amount of data, which cannot be achieved by the RPC.
索引器还允许进行复杂查询、根据不同标准轻松过滤数据以及提取后分析数据。一些索引器还允许聚合来自多个来源的数据,从而避免在多链 dApp 中部署多个 API。通过分布在多个节点上,索引器提供了增强的安全性和性能,而 RPC 提供商可能会因其集中式特性而出现中断和停机。
Indexors also allow complex queries, easy filtering of data according to different standards, and analysis of data after extraction. Some indexers also allow the aggregation of data from multiple sources, thus avoiding the deployment of multiple APIs in multi-chain dApps. By distributing them over multiple nodes, indexers provide enhanced security and performance, while RPC providers may be interrupted and disabled by their centralized properties.
总体而言,与 RPC 节点提供商相比,索引器提高了数据检索的效率和可靠性,同时还降低了部署单个节点的成本。这使得区块链索引器协议成为 dApp 开发人员的首选。
Overall, compared to the RPC node provider, indexers have improved the efficiency and reliability of data retrieval while also reducing the cost of deploying individual nodes. This makes block chain indexer protocols the preferred option for dApp developers.
如前所述,构建 dApp 需要检索和读取区块链数据才能运行其服务。这包括任何类型的 dApp,包括 DeFi、NFT 平台、游戏甚至社交网络,因为这些平台需要先读取数据才能执行其他交易。
As already mentioned, building dApp requires searching and reading block chain data in order to run its services. This includes any type of dApp, including the DeFi, NFT platforms, games and even social networks, as these platforms need to read data before executing other transactions.
DeFi
DeFi 协议需要不同的信息才能为用户报出特定的价格、比率、费用等。自动做市商 (AMM) 需要有关某些资金池的价格和流动性信息来计算掉期利率,而借贷协议则需要利用率来确定借贷利率和清算的债务比率。在计算用户执行的利率之前,将信息输入他们的 dApp 是必不可少的。
The DeFi agreement requires different information in order to report a particular price, ratio, cost, etc. for the user. Automatic marketers (AMM) need information on the price and liquidity of certain pools to calculate the swap rate, while the loan agreement requires utilization to determine the interest rate of the loan and the debt ratio of the settlement.
游戏
GameFi 需要快速索引和访问数据,以确保用户流畅地玩游戏。只有通过闪电般的数据检索和执行,Web3 游戏才能在性能上与 Web2 游戏相媲美,从而吸引更多用户。这些游戏需要土地所有权、游戏内代币余额、游戏内操作等数据。使用索引器,他们可以更好地确保稳定的数据流和稳定的正常运行时间,以确保完美的游戏体验。
GameFi needs quick indexing and access to data to ensure that users can play games freely. Only through lightning-like data retrieval and implementation, Web3 games can be comparable in performance to the Web2 game, thereby attracting more users. These games require data such as land ownership, intergenerational balance of the game, and in-playing of the game. Using indexers, they can better ensure a stable flow of data and a stable normal running time to ensure a perfect game experience.
NFT
NFT 市场和借贷平台需要索引数据访问各种信息,例如 NFT 元数据、所有权和转让数据、版税信息等。快速索引此类数据可避免逐个浏览每个 NFT 以查找所有权或 NFT 属性数据。
The NFT market and lending platform requires indexed data to access a variety of information, such as NFT metadata, ownership and transfer data, royalties information, etc. A quick index of this type would avoid browsing each NFT on a case-by-case basis to find ownership or NFT attribute data.
无论是需要价格和流动性信息的 DeFi 自动做市商 (AMM),还是需要更新新用户帖子的 SocialFi 应用程序,能够快速检索数据对于 dApp 正常运行至关重要。借助索引器,它们可以高效、正确地检索数据,从而提供流畅的用户体验。
Whether DeFi is an automatic marketer (AMM) that requires price and liquidity information, or the SocialFi application that needs to update a new user post, the ability to quickly retrieve data is essential for dApp’s proper operation. With indexers, they can efficiently and correctly retrieve data, thus providing a fluid user experience.
索引器提供了一种从原始区块链数据(包括每个区块中的智能合约事件)中提取特定数据的方法。这为更具体的数据分析提供了机会,从而提供全面的见解。
The indexer provides a method for extracting specific data from the original block chain data, including smart contract events in each block. This provides an opportunity for more specific data analysis and thus provides a comprehensive insight.
例如,永续交易协议可以找出哪些代币的交易量大,哪些代币会产生费用,从而决定是否将这些代币作为永续合约列在其平台上。DEX 开发人员可以为自己的产品创建仪表板,深入了解哪些资金池的回报率最高或流动性最强。还可以创建公共仪表板,让开发人员可以自由灵活地查询要在图表上显示的任何类型的数据。
For example, a sustainable trading agreement can identify the large transactions and the costs associated with them, so that a decision can be made as a permanent contract on its platform. DEX developers can create dashboards for their products to understand in depth which pools have the highest rate of return or are most mobile. Public dashboards can also be created, allowing developers to search freely and flexibly for any type of data to be displayed on the chart.
由于有多个区块链索引器可用,因此识别索引协议之间的差异对于确保开发人员选择最适合其需求的索引器至关重要。
As multiple block chain indexers are available, identifying differences in index protocols is essential to ensure that developers select indexers that are best suited to their needs.
The Graph
The Graph 是第一个在以太坊上启动的索引器协议,它可以轻松查询以前不易访问的交易数据。它使用子图定义和过滤从区块链收集的数据子集,例如与 Uniswap v3 USDC/ETH 池相关的所有交易。
The Graph is the first indexer protocol to be launched in Ether, which allows easy access to previously inaccessible transaction data. It uses subcharts to define and filter the subsets of data collected from block chains, such as all transactions associated with Uniswap v3 USDC/ETH pools.
使用索引证明,索引器质押原生代币 GRT 用于索引和查询服务,委托人可以选择将其代币质押于此。策展人可以访问高质量的子图,以帮助索引器确定要为哪些子图编制数据以赚取最佳查询费用。在向更大程度的去中心化过渡的过程中,The Graph 最终将停止其托管服务,并要求子图升级到其网络,同时提供升级索引器。
Using index proof, the indexer pledges the original intergenerational GRT for indexing and querying services, and the client can choose to pledge its insignia here. The discussant can access high-quality subcharts to help the indexer to determine which subcharts are to be compiled for the best search cost. In the transition to greater decentralisation, The Graph will eventually stop its hosting service and require the sub-chart to be upgraded to its network and to provide an up-to-date indexer.
其基础设施使每百万次查询的平均成本达到 40 美元,这比自托管节点的成本要低得多。使用文件数据源,它还支持同时对链上和链下数据进行并行索引,以实现高效的数据检索。
Its infrastructure amounts to an average cost of $40 per million queries, which is much lower than that of hosting nodes. Using file data sources, it also supports parallel indexing of data on and below the chain to achieve efficient data retrieval.
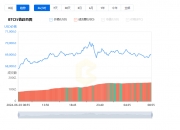
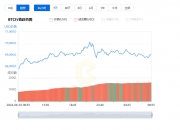
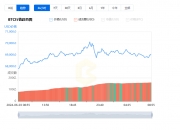
看看 The Graph 的索引器奖励,它在过去几个季度中一直在稳步增长。这部分是由于查询量的增加,但也归因于代币价格的增长,因为他们计划在未来整合人工智能辅助查询。
Look at The Graph's indexer reward, which has been growing steadily over the past few quarters. This is partly due to the increase in the number of queries, but also to the increase in the price of money, because they plan to integrate artificial intelligence aids in the future.
Subsquid
Subsquid 是一个点对点、水平可扩展的去中心化数据湖,可高效聚合大量链上和链下数据,并通过零知识证明进行保护。作为一个去中心化的工作器网络,每个节点负责存储来自特定区块子集的数据,通过快速识别保存所需数据的节点来加快数据检索过程。
Subsquid is a point-to-point, horizontally scalable decentralised data lake that efficiently aggregates a large amount of data on and below the chain and protects it through proof of zero knowledge. As a decentralised network of workmen, each node is responsible for storing data from a subset of specific blocks, accelerating the data retrieval process by quickly identifying nodes to store the data required.
Subsquid 还支持实时索引,允许在区块最终确定之前对其进行索引。它还支持以开发人员选择的格式存储数据,从而便于使用 BigQuery、Parquet 或 CSV 等工具进行更轻松的分析。此外,子图可以在 Subsquid 网络上部署,而无需迁移到 Squid SDK,从而实现无代码部署。
Subsquid also supports real-time indexing, allowing it to be indexed before blocks are finalized. It also supports data storage in formats selected by developers, thus facilitating easier analysis using tools such as BigQuery, Parquet or CSV. In addition, subcharts can be deployed on the Subsquid network without having to migrate to Squid SDK, thus achieving uncoded deployment.
尽管仍处于测试网阶段,Subsquid 已取得令人印象深刻的统计数据,拥有超过 80,000 名测试网用户,部署了超过 60,000 个 Squid 索引器,网络上有超过 20,000 名经过验证的开发人员。最近,6 月 3 日,Subsquid 启动了其数据湖的主网。
Although still in the testing network phase, Subsquid has obtained impressive statistics, has over 80,000 test network users, has over 60,000 Squid indexers and has over 20,000 certified developers on the network. Most recently, on 3 June, Subsquid launched its data lake main network.
除了索引之外,Subsquid Network 数据湖还可以替代分析、ZK/TEE 协处理器、AI 代理和 Oracle 等用例中的 RPC。
In addition to the index, the Subsquid Network Data Lake can replace RPC in such cases as analysis, ZK/TEE processor, AI proxy and Oracle.
SubQuery
SubQuery 是一个去中心化的中间件基础设施网络,提供 RPC 和索引数据服务。它最初支持 Polkadot 和 Substrate 网络,现在已扩展到包括 200 多个链。它的工作原理类似于使用索引证明的 The Graph,索引器索引数据并提供查询请求,委托人将股份质押给索引器。然而,它引入了消费者来提交购买订单,以表明索引器的收入有保障,而不是管理者。
Sub Query is a decentralised intermediate infrastructure network that provides RPC and index data services. It initially supported the Polkadot and Substrate networks, which have now expanded to include more than 200 chains. Its working principles are similar to the use of index evidence, The Graph, index data and access requests, and the client pledges shares to the indexer. However, it introduces consumers to submit purchase orders to show that the indexer's income is secure, not the administrator.
它将引入支持分片的 SubQuery 数据节点,以防止每个节点之间不断同步新数据,从而优化查询效率,同时走向更大的去中心化。用户可以选择按每 1000 个请求支付约 1 SQT 代币的计算费用,或通过协议为索引器设置自定义费用。
It will introduce the SubQuery data node, which will support the split, in order to prevent continuous synchronization of new data between each node, thereby optimizing search efficiency and moving towards greater decentralization. Users can choose to pay for the calculation of approximately 1 SQT tokens per 1,000 requests, or to set custom fees for indexers through protocols.
尽管 SubQuery 在今年早些时候才推出其代币,但节点和委托人的发行奖励也以美元价值环比增长,这也代表其平台上提供的查询服务数量不断增加。自 TGE 以来,质押的 SQT 总量已从 600 万增加到 1.25 亿,凸显了其网络参与度的增长。
Although SubQuery introduced its tokens only earlier this year, nodes and client awards have also grown in dollar value ring terms, representing an increase in the number of query services available on its platform. Since TGE, the total number of SQT pledges has increased from 6 million to 125 million, highlighting the growth in its network participation.
Covalent
Covalent 是一个去中心化的索引器网络,由区块样本生产者(BSP)网络节点通过批量导出的方式创建区块链数据的副本,并在 Covalent L1 区块链上发布证明。这些数据再由区块结果生产者(BRP)节点根据设定的规则进行细化,筛选出符合要求的数据。
Covalent is a network of decentralised indexers, created by block sample producers (BSP) network nodes through bulk export of a copy of block chain data and published a certificate on the Covalent L1 block chain. The data are then fine-tuned by the block result producers (BRP) nodes in accordance with the established rules to screen the required data.
通过统一的 API,开发人员可以轻松以一致的请求和响应格式提取相关的区块链数据,无需编写自定义复杂查询即可访问数据。可以使用在 Moonbeam 上结算的 CQT 代币作为支付手段从网络运营商处提取这些预配置的数据集。
Through a unified API, developers can easily extract the relevant block chain data in a consistent request and response format, without having to prepare a self-defined complex query to access the data. These preconfigured data sets can be extracted from network operators using CQT tokens that are settled on Moonbeam as a means of payment.
Covalent 的奖励从 23 年第一季度到 24 年第一季度似乎总体呈增长趋势,部分原因是 Covalent 代币 CQT 价格上涨。
The Covalent incentive appears to have generally increased from the first quarter of 23 to the first quarter of 24, partly because of the CQT price increase.
数据的可定制性
一些索引器(例如 Covalent)是通用索引器,仅通过 API 提供标准的预配置数据集。虽然它们可能很快,但它们无法为需要自定义数据集的开发人员提供灵活性。通过使用索引器框架,它允许进行更多自定义数据处理以满足特定于应用程序的需求。
Some indexers (e.g. Covalent) are generic indexers that provide standard pre-configuration data sets only through API. Although they may be quick, they cannot provide flexibility for developers who need a custom data set. By using the index frame, it allows for more custom data processing to meet application-specific needs.
安全
索引数据必须是安全的,否则基于这些索引器构建的 dApp 也容易受到攻击。例如,如果交易和钱包余额可以被操纵,dApp 就有可能失去流动性,从而影响其用户。虽然所有索引器都通过索引器质押代币来采用某种形式的安全性,但其他索引器解决方案可能会使用证明来进一步提高安全性。
Indexed data must be secure, otherwise dApps constructed on the basis of these indexers are also vulnerable to attack. For example, if transaction and wallet balances can be manipulated, dApp may lose its liquidity, thereby affecting its users. While all indexers use the indexers to pledge their currencies with some form of security, other indexer solutions may use proof to further enhance security.
Subsquid 提供了使用乐观和零知识证明的选项,而 Covalent 还发布了包含区块哈希值的证明。Graph 以乐观挑战窗口期的方式针对索引器查询提供争议挑战期,而 SubQuery 为每个区块生成 Merkle Mountain 证明,以计算其数据库中存储的所有数据的每个区块的哈希值。
Subsquid offers the option of using optimistic and zero-knowledge certificates, while Covalent also publishes certificates containing block Hashi values. Graph provides a contentious challenge period for index queries in an optimistic challenge window period, while SubQuery generates Merkle Mountain certificates for each block to calculate the Hashi values for each block of all data stored in its database.
速度和可扩展性
随着区块链的不断增长,交易量也随之增加,这使得索引大量数据变得更加繁琐,因为需要更多的处理能力和存储空间。随着区块链网络的增长,保持效率变得更加困难,但索引器协议引入了解决方案来满足这些日益增长的需求。
As the block chain grows, so does the volume of transactions, which makes indexing of large amounts of data more cumbersome because of the need for more processing capacity and storage space. As the block chain network grows, maintaining efficiency becomes more difficult, but the indexer protocol introduces solutions to meet these growing demands.
例如,Subsquid 通过添加更多节点来存储数据,从而实现水平扩展,随着硬件改进,它能够扩展。Graph 提供并行流数据,以更快地同步数据,而 SubQuery 引入节点分片来加快同步过程。
Subsquid, for example, enables horizontal expansion by adding more nodes to store data, which can be expanded as hardware improves. Graph provides parallel flow data to allow faster synchronization of data, while SubQuery introduces nodes to accelerate synchronization.
支持的网络
尽管大多数区块链活动仍在以太坊内进行,但随着时间的推移,不同的区块链越来越受欢迎。例如,Layer 2s、Solana、Move 区块链和比特币生态系统链都有自己的一套不断增长的开发人员和活动,这也需要索引服务。
Although most block chain activities continue to take place in the Taiku, different block chains have become more popular over time. For example, the Layer 2s, Solana, Move block chain and the Bitcoin ecosystem chain have their own set of growing developers and activities, which also require indexing services.
为其他索引器协议不支持的某些链提供支持可以获得更多市场份额费用。索引数据密集型网络(如 Solana)并非易事,到目前为止,只有 Subsquid 成功为它们提供索引支持。
The index data-intensive network (e.g. Solana) is not easy, and so far only Subsquid has succeeded in providing them with index support.
尽管索引器在 dApp 开发中被广泛采用,但索引器的潜力仍然巨大,尤其是在集成 AI 的情况下。随着 AI 在 Web2 和 Web3 中的不断普及,其改进能力取决于访问相关数据以训练模型和开发 AI 代理。确保数据完整性对于 AI 应用程序至关重要,因为它可以防止模型被输入有偏见或不准确的信息。
While indexers are widely used in dApp development, they still have great potential, especially in the case of integrated AI. As AI becomes more widely available in Web2 and Web3, its ability to improve depends on accessing relevant data to train models and develop AI agents. Ensuring data integrity is essential for AI applications, as it prevents models from entering biased or inaccurate information.
在索引器解决方案领域,Subsquid 在性能和用户指标方面取得了重大进展。用户已经开始尝试使用 Subsquid 构建 AI 代理,展示了该平台在不断发展的数据索引领域的多功能性和潜力。此外,AutoAgora 等工具帮助索引器使用 AI 为 The Graph 上的查询服务提供动态定价,而 SubQuery 支持多个 AI 网络(如 OriginTrail 和 Oraichain),以实现透明的数据索引。
In the indexer solution area, Subsquid has made significant progress in performance and user indicators. Users have begun to try to build AI agents using Subsquid, demonstrating the platform's multifunctionality and potential in the evolving area of data indexing. In addition, tools such as AutoAgora help indexers to use AI for dynamic pricing of query services on The Graph, while SubQuery supports multiple AI networks (e.g. OriginTrail and Oraichain) to achieve transparent data indexing.
人工智能与索引器的集成有望增强区块链生态系统中的数据可访问性和可用性。通过利用人工智能技术,索引器可以提供更高效、更准确的数据检索,使开发人员能够构建更复杂的 dApp 和分析工具。随着人工智能和索引器继续共同发展,我们仍然对数据索引的未来及其在塑造去中心化数字格局中的作用持乐观态度。
The integration of artificial intelligence and indexers is expected to enhance the accessibility and usability of data in block-chain ecosystems. Using artificial intelligence technologies, indexers can provide more efficient and accurate data retrieval, enabling developers to construct more sophisticated dApp and analytical tools.
注册有任何问题请添加 微信:MVIP619 拉你进入群

打开微信扫一扫
添加客服
进入交流群












发表评论