



Qwen2是阿里云最新推出的开源大型语言模型系列,相比Qwen1.5,Qwen2实现了整体性能的代际飞跃,大幅提升了代码、数学、推理、指令遵循、多语言理解等能力。
包含5个尺寸的预训练和指令微调模型:Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B和Qwen2-72B,其中Qwen2-57B-A14B为混合专家模型(MoE)。所有尺寸模型都使用了GQA(分组查询注意力)机制,以便让用户体验到GQA带来的推理加速和显存占用降低的优势。
在中文、英语的基础上,训练数据中增加了27种语言相关的高质量数据。
增大了上下文长度支持,最高达到128K tokens(Qwen2-72B-Instruct)。
本示例目前支持在华北2(北京)、华东2(上海)、华南1(深圳)、华东1(杭州)、华北6(乌兰察布)等地域使用PAI-快速开始(PAI-QuickStart)模块运行。
资源配置要求:
模型规模
要求
Qwen2-0.5b/1.5b/7b
使用V100/P100/T4(16 GB显存)及以上卡型运行训练任务。
Qwen2-72b
使用A100(80 GB显存)及以上卡型运行训练任务,仅支持华北6(乌兰察布)地域。
进入快速开始页面。
登录PAI控制台。
在顶部左上角根据实际情况选择地域。
在左侧导航栏选择工作空间列表,单击指定工作空间名称,进入对应工作空间内。
在左侧导航栏选择快速开始。
在快速开始页面右侧的模型列表中,单击Qwen2-7b-Instruct模型卡片,进入模型详情页面。
单击右上角部署,配置推理服务名称以及部署使用的资源信息,即可将模型部署到EAS推理服务平台。
当前模型需要使用公共资源组进行部署。
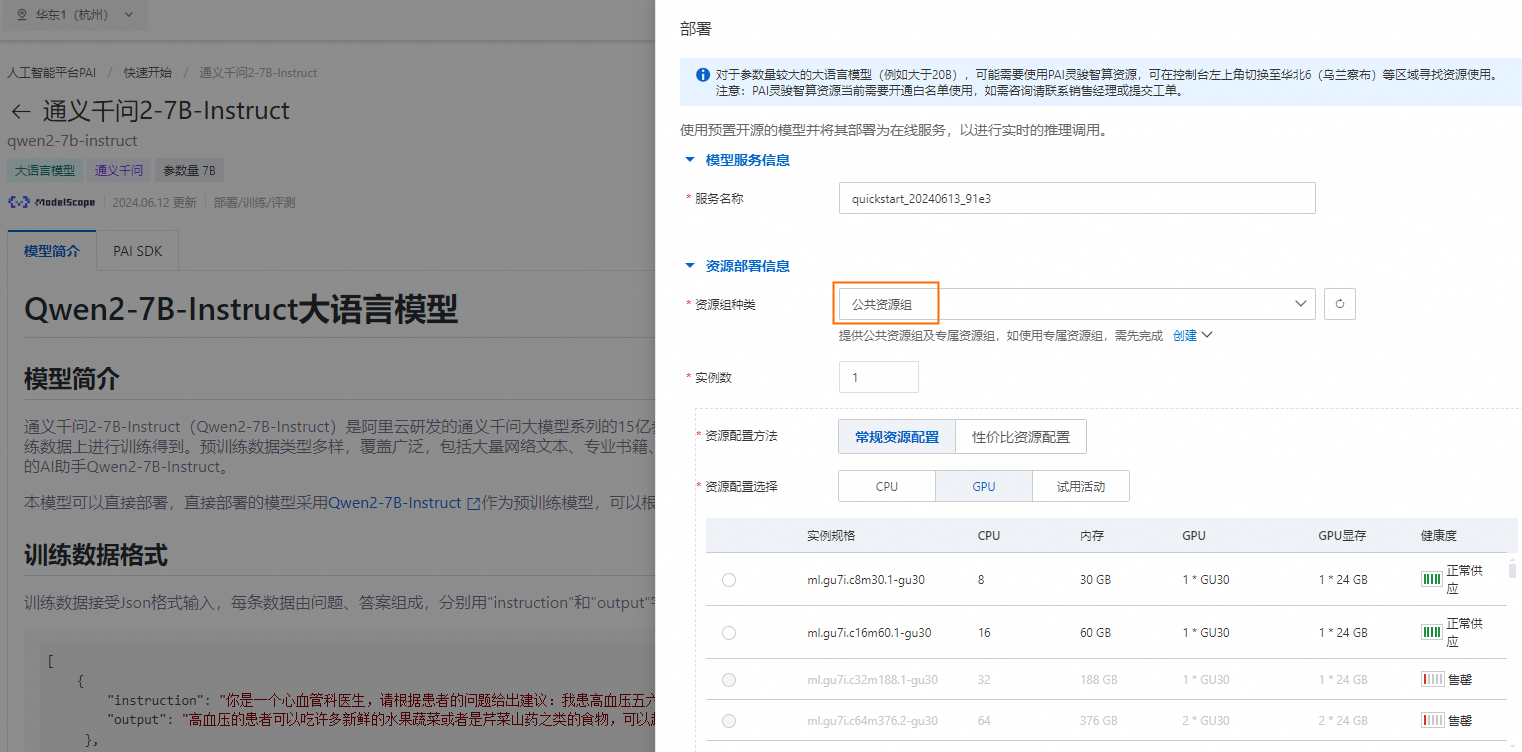
使用推理服务。
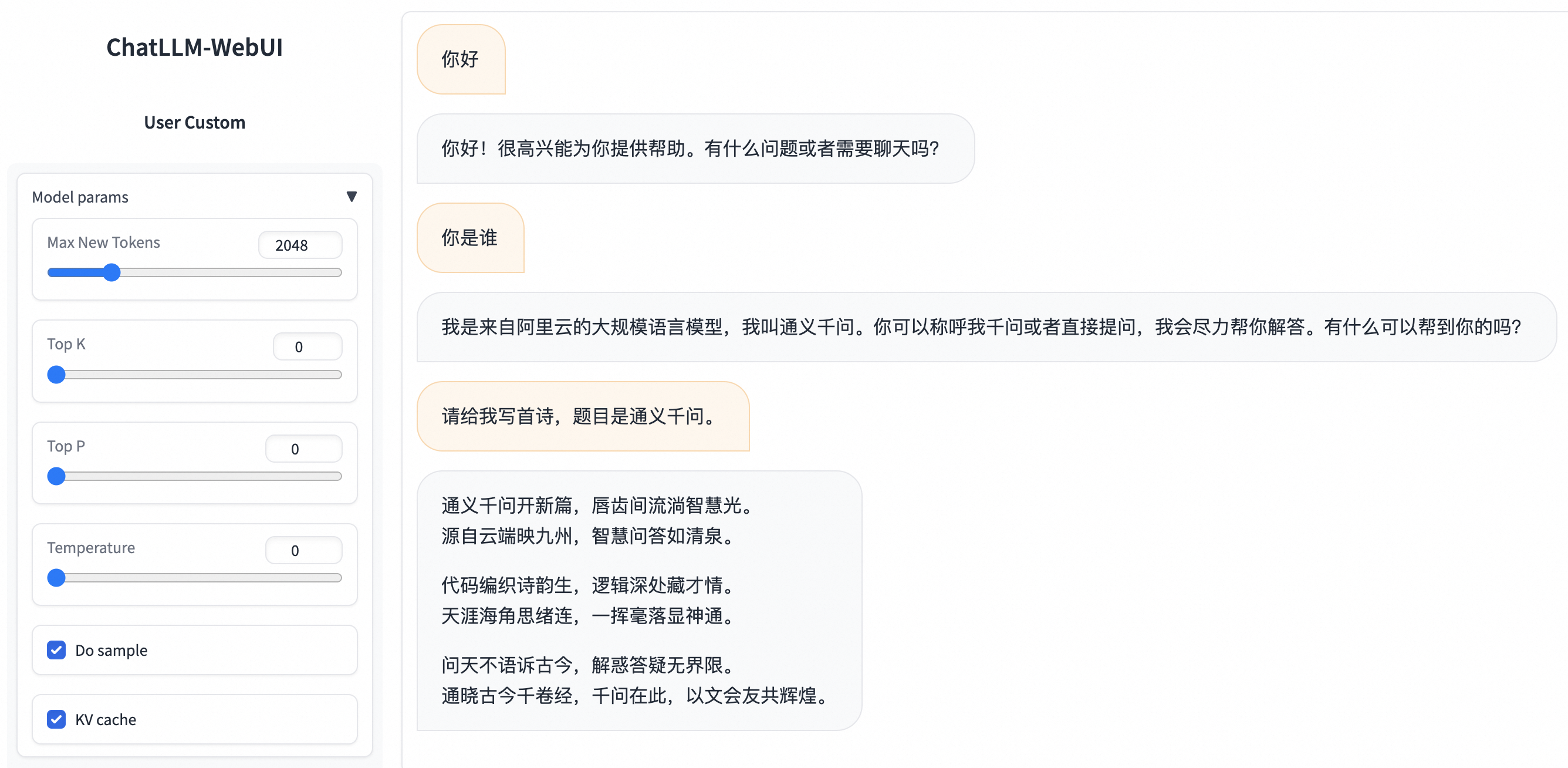
在任务管理中单击已部署的服务名称,在服务详情页面单击查看WEB应用,即可通过ChatLLM WebUI进行实时交互。
PAI-QuickStart为Qwen2-7b-Instruct模型配置了微调算法,您可以通过开箱即用的方式对该模型进行微调。
训练算法支持使用JSON格式输入,每条数据由问题、答案组成,分别用、字段表示,例如:
在模型详情页单击右上角微调训练。关键配置如下:
数据集配置:当完成数据的准备,您可以将数据上传到对象存储OSS Bucket中,或是通过指定一个数据集对象,选择NAS或CPFS存储上的数据集。您也可以使用PAI预置的公共数据集,直接提交任务测试算法。
计算资源配置:算法需要使用V100/P100/T4(16GB显存)的GPU资源,请确保选择使用的资源配额内有充足的计算资源。
超参数配置:训练算法支持的超参信息如下,您可以根据使用的数据,计算资源等调整超参,或是使用算法默认配置的超参。
超参数
类型
默认值
是否必须
描述
learning_rate
float
5e-5
是
学习率,用于控制模型权重,调整幅度。
num_train_epochs
int
1
是
训练数据集被重复使用的次数。
per_device_train_batch_size
int
1
是
每个GPU在一次训练迭代中处理的样本数量。较大的批次大小可以提高效率,也会增加显存的需求。
seq_length
int
128
是
序列长度,指模型在一次训练中处理的输入数据的长度。
lora_dim
int
32
否
LoRA维度,当lora_dim>0时,使用LoRA/QLoRA轻量化训练。
lora_alpha
int
32
否
LoRA权重,当lora_dim>0时,使用LoRA/QLoRA轻量化训练,该参数生效。
load_in_4bit
bool
true
否
模型是否以4 bit加载。
当lora_dim>0、load_in_4bit为true且load_in_8bit为false时,使用4 bit QLoRA轻量化训练。
load_in_8bit
bool
false
否
模型是否以8比特加载。
当lora_dim>0、load_in_4bit为false且load_in_8bit为true时,使用8 bit QLoRA轻量化训练。
gradient_accumulation_steps
int
8
否
梯度累积步骤数。
apply_chat_template
bool
true
否
算法是否为训练数据加上模型默认的chat template,以Qwen2系列模型为例,格式为:
问题:
答案:
system_prompt
string
You are a helpful assistant
否
模型训练使用的系统提示语。
单击训练,PAI-QuickStart自动跳转到模型训练页面,并开始进行训练,您可以查看训练任务状态和训练日志。
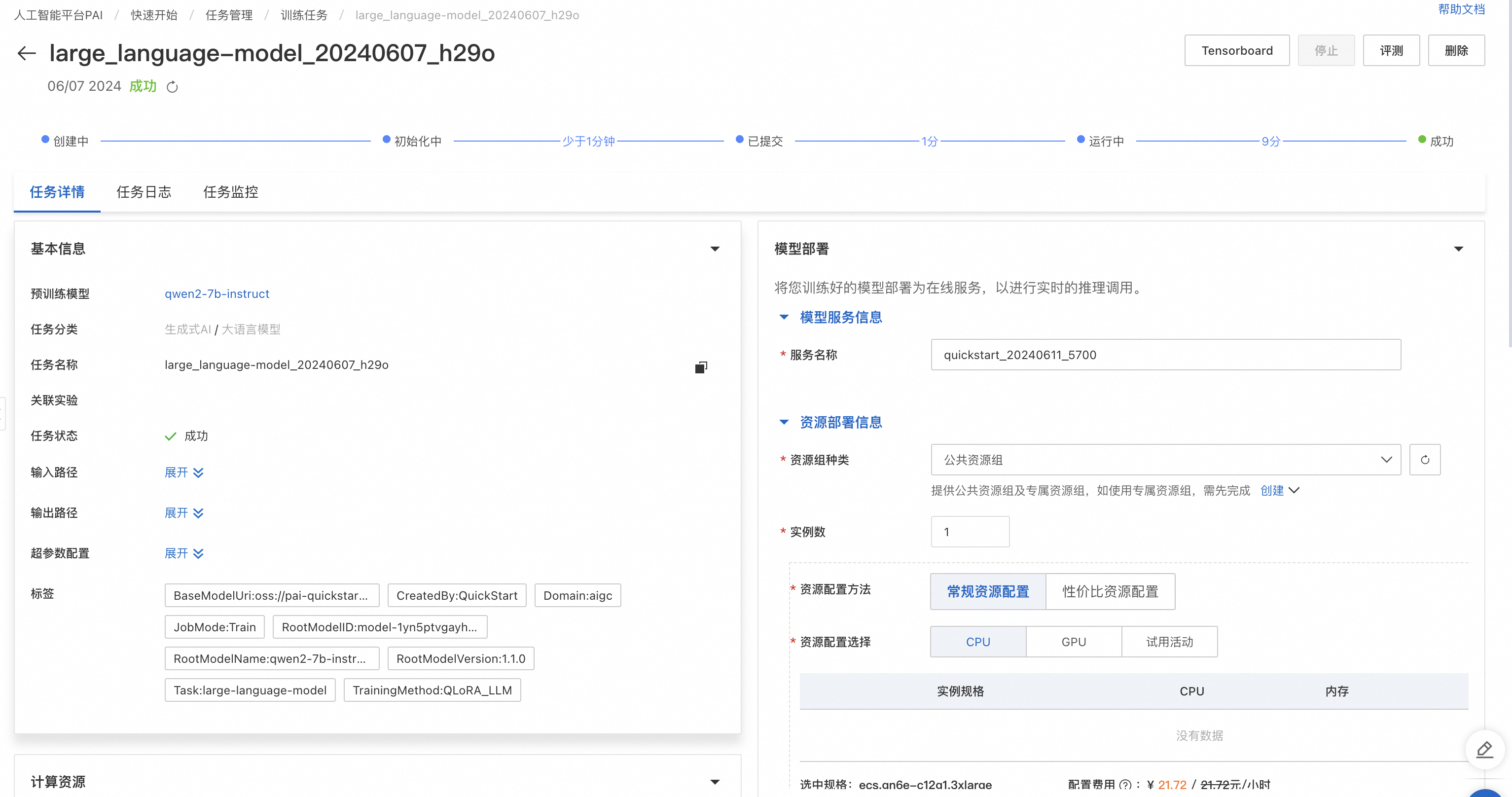
如果需要将微调训练完的模型部署为在线服务,可以在同一页面的模型部署卡片中选择资源组,然后单击部署实现一键部署。模型调用方式和上文直接部署模型的调用方式相同。
科学、高效的模型评测,不仅能帮助开发者有效地衡量和对比不同模型的性能,更能指导他们进行精准地模型选择和优化,加速AI创新和应用落地。
PAI-QuickStart为Qwen2-7b-Instruct模型配置了评测算法,您可以通过开箱即用的方式对该模型(或微调后的模型)进行评测。关于模型评测详细的操作说明,请参见大模型评测最佳实践。
PAI-QuickStart提供的预训练模型也支持通过PAI Python SDK进行调用,首先需要安装和配置PAI Python SDK,您可以在命令行执行以下代码:
如何获取SDK配置所需的访问凭证(AccessKey)、PAI工作空间等信息请参考安装和配置。
通过PAI-QuickStart在模型上预置的推理服务配置,您可轻松地将Qwen2-7b-Instruct模型部署到PAI-EAS推理平台。
通过SDK获取PAI-QuickStart提供的预训练模型后,您可以对模型进行微调。
通过快速开始的模型卡片详情页,您可以通过在DSW中打开入口,获取一个完整的Notebook示例,了解如何通过PAI Python SDK使用的细节。
更多关于如何通过SDK使用PAI-QuickStart提供的预训练模型,请参见使用预训练模型 — PAI Python SDK。
注册有任何问题请添加 微信:MVIP619 拉你进入群

打开微信扫一扫
添加客服
进入交流群












发表评论